
Lambda
Founded Year
2012Stage
Line of Credit | AliveTotal Raised
$393.15MValuation
$0000Revenue
$0000Mosaic Score The Mosaic Score is an algorithm that measures the overall financial health and market potential of private companies.
+52 points in the past 30 days
About Lambda
Lambda provides computation solutions in the technology sector. It offers a range of products, including GPU clouds, clusters, servers, and workstations designed to accelerate deep learning and AI processes. Lambda primarily serves sectors such as research, defense, and entertainment. The company was founded in 2012 and is based in San Jose, California.
Loading...
Lambda's Product Videos


ESPs containing Lambda
The ESP matrix leverages data and analyst insight to identify and rank leading companies in a given technology landscape.
The cloud graphics processing unit (GPU) market offers compelling reasons for customer interest by providing powerful computational resources for graphics-intensive and parallel processing workloads. This market focuses on delivering GPU capabilities through cloud-based platforms, enabling users to leverage high-performance computing without the need for on-premises infrastructure. By investing in…
Lambda named as Challenger among 15 other companies, including Advanced Micro Devices, NVIDIA, and IBM.
Lambda's Products & Differentiators
GPU Cloud
Dedicated GPU instances combined with a full suite of ML softwares and tooling that 'just work'.
Loading...
Research containing Lambda
Get data-driven expert analysis from the CB Insights Intelligence Unit.
CB Insights Intelligence Analysts have mentioned Lambda in 2 CB Insights research briefs, most recently on Nov 7, 2024.
Sep 13, 2024
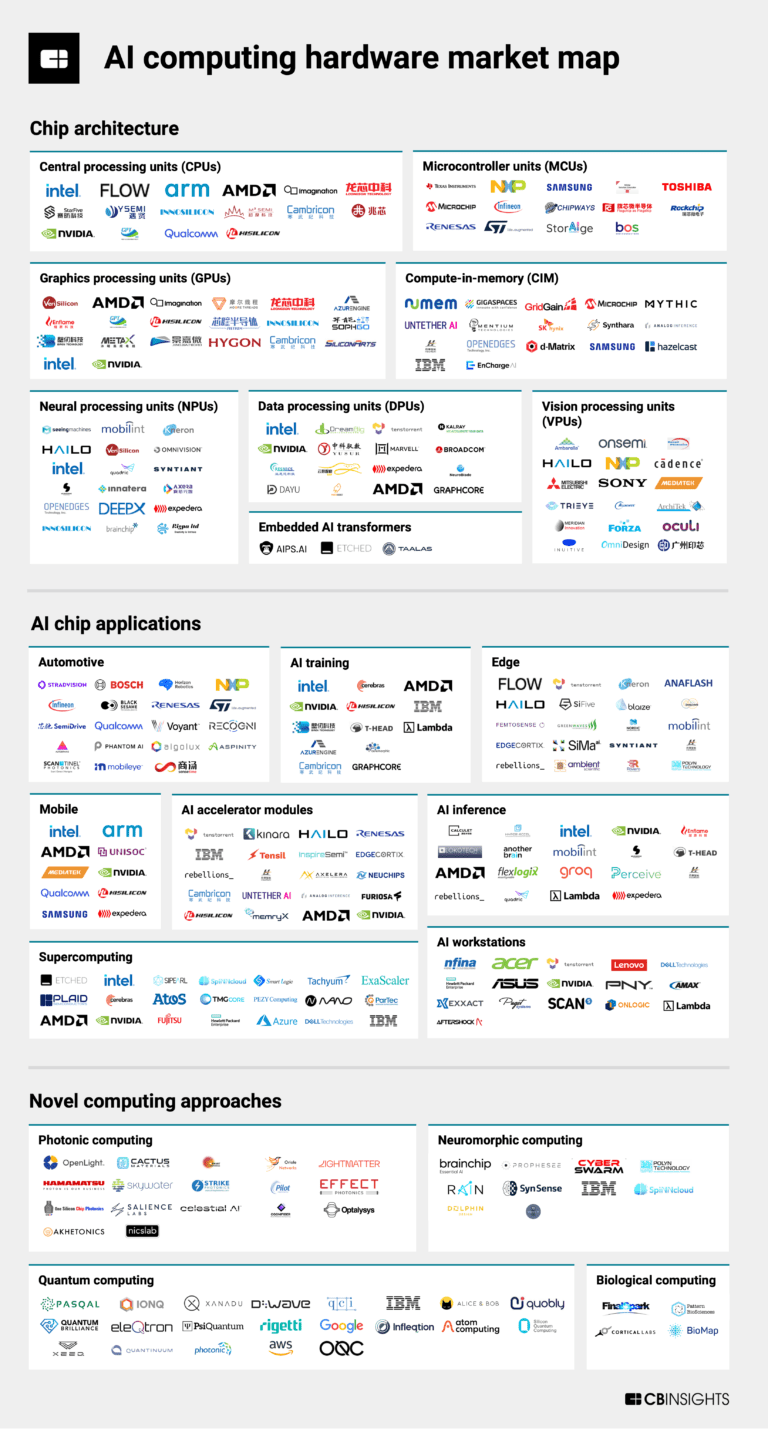
The AI computing hardware market mapExpert Collections containing Lambda
Expert Collections are analyst-curated lists that highlight the companies you need to know in the most important technology spaces.
Lambda is included in 3 Expert Collections, including Unicorns- Billion Dollar Startups.
Unicorns- Billion Dollar Startups
1,258 items
Semiconductors, Chips, and Advanced Electronics
7,286 items
Companies in the semiconductors & HPC space, including integrated device manufacturers (IDMs), fabless firms, semiconductor production equipment manufacturers, electronic design automation (EDA), advanced semiconductor material companies, and more
Artificial Intelligence
7,146 items
Lambda Patents
Lambda has filed 6 patents.
The 3 most popular patent topics include:
- communication circuits
- radio electronics
- analog circuits
Application Date | Grant Date | Title | Related Topics | Status |
|---|---|---|---|---|
5/7/2024 | 9/10/2024 | Oscillators, Laser science, Spectroscopy, Communication circuits, Telecommunication theory | Grant |
Application Date | 5/7/2024 |
|---|---|
Grant Date | 9/10/2024 |
Title | |
Related Topics | Oscillators, Laser science, Spectroscopy, Communication circuits, Telecommunication theory |
Status | Grant |
Latest Lambda News
Jan 15, 2025
Implement RAG while meeting data residency requirements using AWS hybrid and edge services Like Views: 1 With the general availability of Amazon Bedrock Agents , you can rapidly develop generative AI applications to run multi-step tasks across a myriad of enterprise systems and data sources. However, some geographies and regulated industries bound by data protection and privacy regulations have sought to combine generative AI services in the cloud with regulated data on premises. In this post, we show how to extend Amazon Bedrock Agents to hybrid and edge services such as AWS Outposts and AWS Local Zones to build distributed Retrieval Augmented Generation (RAG) applications with on-premises data for improved model outcomes. With Outposts, we also cover a reference pattern for a fully local RAG application that requires both the foundation model (FM) and data sources to reside on premises. Solution overview For organizations processing or storing sensitive information such as personally identifiable information (PII), customers have asked for AWS Global Infrastructure to address these specific localities, including mechanisms to make sure that data is being stored and processed in compliance with local laws and regulations. Through AWS hybrid and edge services such as Local Zones and Outposts, you can benefit from the scalability and flexibility of the AWS Cloud with the low latency and local processing capabilities of an on-premises (or localized) infrastructure. This hybrid approach allows organizations to run applications and process data closer to the source, reducing latency, improving responsiveness for time-sensitive workloads, and adhering to data regulations. Although architecting for data residency with an Outposts rack and Local Zone has been broadly discussed, generative AI and FMs introduce an additional set of architectural considerations. As generative AI models become increasingly powerful and ubiquitous, customers have asked us how they might consider deploying models closer to the devices, sensors, and end users generating and consuming data. Moreover, interest in small language models (SLMs) that enable resource-constrained devices to perform complex functions—such as natural language processing and predictive automation—is growing. To learn more about opportunities for customers to use SLMs, see Opportunities for telecoms with small language models: Insights from AWS and Meta on our AWS Industries blog. Beyond SLMs, the interest in generative AI at the edge has been driven by two primary factors: Latency – Running these computationally intensive models on an edge infrastructure can significantly reduce latency and improve real-time responsiveness, which is critical for many time-sensitive applications like virtual assistants, augmented reality, and autonomous systems. Privacy and security – Processing sensitive data at the edge, rather than sending it to the cloud, can enhance privacy and security by minimizing data exposure. This is particularly useful in healthcare, financial services, and legal sectors. In this post, we cover two primary architectural patterns: fully local RAG and hybrid RAG. Fully local RAG For the deployment of a large language model (LLM) in a RAG use case on an Outposts rack, the LLM will be self-hosted on a G4dn instance and knowledge bases will be created on the Outpost rack, using either Amazon Elastic Block Storage (Amazon EBS) or Amazon S3 on Outposts . The documents uploaded to the knowledge base on the rack might be private and sensitive documents, so they won’t be transferred to the AWS Region and will remain completely local on the Outpost rack. You can use a local vector database either hosted on Amazon Elastic Compute Cloud (Amazon EC2) or using Amazon Relational Database Service (Amazon RDS) for PostgreSQL on the Outpost rack with the pgvector extension to store embeddings. See the following figure for an example. Hybrid RAG Certain customers are required by data protection or privacy regulations to keep their data within specific state boundaries. To align with these requirements and still use such data for generative AI, customers with hybrid and edge environments need to host their FMs in both a Region and at the edge. This setup enables you to use data for generative purposes and remain compliant with security regulations. To orchestrate the behavior of such a distributed system, you need a system that can understand the nuances of your prompt and direct you to the right FM running in a compliant environment. Amazon Bedrock Agents makes this distributed system in hybrid systems possible. Amazon Bedrock Agents enables you to build and configure autonomous agents in your application. Agents orchestrate interactions between FMs, data sources, software applications, and user conversations. The orchestration includes the ability to invoke AWS Lambda functions to invoke other FMs, opening the ability to run self-managed FMs at the edge. With this mechanism, you can build distributed RAG applications for highly regulated industries subject to data residency requirements. In the hybrid deployment scenario, in response to a customer prompt, Amazon Bedrock can perform some actions in a specified Region and defer other actions to a self-hosted FM in a Local Zone. The following example illustrates the hybrid RAG high-level architecture. In the following sections, we dive deep into both solutions and their implementation. Fully local RAG: Solution deep dive To start, you need to configure your virtual private cloud (VPC) with an edge subnet on the Outpost rack. To create an edge subnet on the Outpost, you need to find the Outpost Amazon Resource Name (ARN) on which you want to create the subnet, as well as the Availability Zone of the Outpost. After you create the internet gateway, route tables, and subnet associations, launch a series of EC2 instances on the Outpost rack to run your RAG application, including the following components. Vector store – To support RAG (Retrieval-Augmented Generation), deploy an open-source vector database, such as ChromaDB or Faiss, on an EC2 instance (C5 family) on AWS Outposts. This vector database will store the vector representations of your documents, serving as a key component of your local Knowledge Base. Your selected embedding model will be used to convert text (both documents and queries) into these vector representations, enabling efficient storage and retrieval. The actual Knowledge Base consists of the original text documents and their corresponding vector representations stored in the vector database. To query this knowledge base and generate a response based on the retrieved results, you can use LangChain to chain the related documents retrieved by the vector search to the prompt fed to your Large Language Model (LLM). This approach allows for retrieval and integration of relevant information into the LLM’s generation process, enhancing its responses with local, domain-specific knowledge. Chatbot application – On a second EC2 instance (C5 family), deploy the following two components: a backend service responsible for ingesting prompts and proxying the requests back to the LLM running on the Outpost, and a simple React application that allows users to prompt a local generative AI chatbot with questions. LLM or SLM– On a third EC2 instance (G4 family), deploy an LLM or SLM to conduct edge inferencing via popular frameworks such as Ollama . Additionally, you can use ModelBuilder using the SageMaker SDK to deploy to a local endpoint, such as an EC2 instance running at the edge. Optionally, your underlying proprietary data sources can be stored on Amazon Simple Storage Service (Amazon S3) on Outposts or using Amazon S3-compatible solutions running on Amazon EC2 instances with EBS volumes. The components intercommunicate through the traffic flow illustrated in the following figure. The workflow consists of the following steps: Using the frontend application, the user uploads documents that will serve as the knowledge base and are stored in Amazon EBS on the Outpost rack. These documents are chunked by the application and are sent to the embedding model. The embedding model, which is hosted on the same EC2 instance as the local LLM API inference server, converts the text chunks into vector representations. The generated embeddings are sent to the vector database and stored, completing the knowledge base creation. Through the frontend application, the user prompts the chatbot interface with a question. The prompt is forwarded to the local LLM API inference server instance, where the prompt is tokenized and is converted into a vector representation using the local embedding model. The question’s vector representation is sent to the vector database where a similarity search is performed to get matching data sources from the knowledge base. After the local LLM has the query and the relevant context from the knowledge base, it processes the prompt, generates a response, and sends it back to the chatbot application. The chatbot application presents the LLM response to the user through its interface. To learn more about the fully local RAG application or get hands-on with the sample application, see Module 2 of our public AWS Workshop: Hands-on with Generative AI on AWS Hybrid & Edge Services . Hybrid RAG: Solution deep dive To start, you need to configure a VPC with an edge subnet, either corresponding to an Outpost rack or Local Zone depending on the use case. After you create the internet gateway, route tables, and subnet associations, launch an EC2 instance on the Outpost rack (or Local Zone) to run your hybrid RAG application. On the EC2 instance itself, you can reuse the same components as the fully local RAG: a vector store, backend API server, embedding model and a local LLM. In this architecture, we rely heavily on managed services such as Lambda and Amazon Bedrock because only select FMs and knowledge bases corresponding to the heavily regulated data, rather than the orchestrator itself, are required to live at the edge. To do so, we will extend the existing Amazon Bedrock Agents workflows to the edge using a sample FM-powered customer service bot . In this example customer service bot, we’re a shoe retailer bot that provides customer service support for purchasing shoes by providing options in a human-like conversation. We also assume that the knowledge base surrounding the practice of shoemaking is proprietary and, therefore, resides at the edge. As a result, questions surrounding shoemaking will be addressed by the knowledge base and local FM running at the edge. To make sure that the user prompt is effectively proxied to the right FM, we rely on Amazon Bedrock Agents action groups. An action group defines actions that the agent can perform, such as place_order or check_inventory. In our example, we could define an additional action within an existing action group called hybrid_rag or learn_shoemaking that specifically addresses prompts that can only be addressed by the AWS hybrid and edge locations. As part of the agent’s InvokeAgent API, an agent interprets the prompt (such as “How is leather used for shoemaking?”) with an FM and generates a logic for the next step it should take, including a prediction for the most prudent action in an action group. In this example, we want the prompt, “Hello, I would like recommendations to purchase some shoes.” to be directed to the /check_inventory action group, whereas the prompt, “How is leather used for shoemaking?” could be directed to the /hybrid_rag action group. The following diagram illustrates this orchestration, which is implemented by the orchestration phase of the Amazon Bedrock agent. To create the additional edge-specific action group, the new OpenAPI schema must reflect the new action, hybrid_rag with a detailed description, structure, and parameters that define the action in the action group as an API operation specifically focused on a data domain only available in a specific edge location. After you define an action group using the OpenAPI specification, you can define a Lambda function to program the business logic for an action group. This Lambda handler (see the following code) might include supporting functions (such as queryEdgeModel) for the individual business logic corresponding to each action group. def lambda_handler(event, context): responses = [] global cursor if cursor == None: cursor = load_data() id = '' api_path = event['apiPath'] logger.info('API Path') logger.info(api_path) if api_path == '/customer/{CustomerName}': parameters = event['parameters'] for parameter in parameters: if parameter["name"] == "CustomerName": cName = parameter["value"] body = return_customer_info(cName) elif api_path == '/place_order': parameters = event['parameters'] for parameter in parameters: if parameter["name"] == "ShoeID": id = parameter["value"] if parameter["name"] == "CustomerID": cid = parameter["value"] body = place_shoe_order(id, cid) elif api_path == '/check_inventory': body = return_shoe_inventory() elif api_path == "/hybrid_rag": prompt = event['parameters'][0]["value"] body = queryEdgeModel(prompt) response_body = {"application/json": {"body": str(body)}} response_code = 200 else: body = {"{} is not a valid api, try another one. ".format(api_path)} response_body = { 'application/json': { 'body': json.dumps(body) } } However, in the action group corresponding to the edge LLM (as seen in the code below), the business logic won’t include Region-based FM invocations, such as using Amazon Bedrock APIs. Instead, the customer-managed endpoint will be invoked, for example using the private IP address of the EC2 instance hosting the edge FM in a Local Zone or Outpost. This way, AWS native services such as Lambda and Amazon Bedrock can orchestrate complicated hybrid and edge RAG workflows. def queryEdgeModel(prompt): import urllib.request, urllib.parse # Composing a payload for API payload = {'text': prompt} data = json.dumps(payload).encode('utf-8') headers = {'Content-type': 'application/json'} # Sending a POST request to the edge server req = urllib.request.Request(url="http://<your-private-ip-address>:5000/", data=data, headers=headers, method='POST') with urllib.request.urlopen(req) as response: response_text = response.read().decode('utf-8') return response_text After the solution is fully deployed, you can visit the chat playground feature on the Amazon Bedrock Agents console and ask the question, “How are the rubber heels of shoes made?” Even though most of the prompts will be be exclusively focused on retail customer service operations for ordering shoes, the native orchestration support by Amazon Bedrock Agents seamlessly directs the prompt to your edge FM running the LLM for shoemaking. To learn more about this hybrid RAG application or get hands-on with the cross-environment application, refer to Module 1 of our public AWS Workshop: Hands-on with Generative AI on AWS Hybrid & Edge Services . Conclusion In this post, we demonstrated how to extend Amazon Bedrock Agents to AWS hybrid and edge services, such as Local Zones or Outposts, to build distributed RAG applications in highly regulated industries subject to data residency requirements. Moreover, for 100% local deployments to align with the most stringent data residency requirements, we presented architectures converging the knowledge base, compute, and LLM within the Outposts hardware itself. To get started with both architectures, visit AWS Workshops . To get started with our newly released workshop, see Hands-on with Generative AI on AWS Hybrid & Edge Services . Additionally, check out other AWS hybrid cloud solutions or reach out to your local AWS account team to learn how to get started with Local Zones or Outposts. About the Authors Robert Belson is a Developer Advocate in the AWS Worldwide Telecom Business Unit, specializing in AWS edge computing. He focuses on working with the developer community and large enterprise customers to solve their business challenges using automation, hybrid networking, and the edge cloud. Aditya Lolla is a Sr. Hybrid Edge Specialist Solutions architect at Amazon Web Services. He assists customers across the world with their migration and modernization journey from on-premises environments to the cloud and also build hybrid architectures on AWS Edge infrastructure. Aditya’s areas of interest include private networks, public and private cloud platforms, multi-access edge computing, hybrid and multi cloud strategies and computer vision applications.
Lambda Frequently Asked Questions (FAQ)
When was Lambda founded?
Lambda was founded in 2012.
Where is Lambda's headquarters?
Lambda's headquarters is located at 2510 Zanker Road, San Jose.
What is Lambda's latest funding round?
Lambda's latest funding round is Line of Credit.
How much did Lambda raise?
Lambda raised a total of $393.15M.
Who are the investors of Lambda?
Investors of Lambda include Industrial Development Funding, Macquarie Group, 1517 Fund, Gradient Ventures, Bloomberg Beta and 18 more.
Who are Lambda's competitors?
Competitors of Lambda include DataCrunch, CoreWeave, TensorWave, The Cloud Minders, Graphcore and 7 more.
What products does Lambda offer?
Lambda's products include GPU Cloud and 3 more.
Loading...
Compare Lambda to Competitors

CoreWeave provides services such as computing, managed Kubernetes, virtual servers, storage solutions, and networking for sectors requiring intensive computational power, including machine learning, visual effects, and rendering services. CoreWeave was formerly known as Atlantic Crypto. It was founded in 2017 and is based in Roseland, New Jersey.

Salad Technologies specializes in leveraging distributed GPU resources for AI/ML inference at scale within the cloud computing industry. It offers a platform that enables the deployment of containerized applications on a global network of consumer-grade GPUs, providing an alternative to traditional cloud services. It caters to various sectors including AI inference, batch processing, and molecular dynamics. The company was founded in 2018 and is based in Salt Lake City, Utah.

ArrayFire specializes in high-performance computing solutions, focusing on GPU and accelerator software within the technology sector. The company offers a comprehensive tensor library for GPU computing, consulting services, and training programs aimed at accelerating code and algorithm performance. ArrayFire's products and services cater to a diverse range of industries that require advanced computing capabilities, such as defense, finance, and media. It was founded in 2007 and is based in Atlanta, Georgia.
io.net focuses on providing artificial intelligence (AI) solutions. The company offers a platform to harness global graphics processing unit (GPU) resources to provide computing power for AI startups, allowing users to create and deploy clusters for machine learning applications. It primarily serves the AI development and cloud computing industries. io.net was formerly known as Antbit. It was founded in 2022 and is based in New York, New York.
The Cloud Minders specializes in scalable GPU cloud computing solutions for the AI and machine learning sectors. It offers supercomputing services designed to accelerate AI training and optimize AI inference, catering to innovators and researchers. The company was founded in 2021 and is based in Atlanta, Georgia.

Cudo Compute provides GPU cloud solutions within the cloud computing industry. The company offers services including virtual machines, bare metal servers, and GPU clusters that support workloads such as AI, machine learning, and rendering. Cudo Compute serves sectors that require computing resources, including the AI and ML industries. It is based in London, England.
Loading...